Bruce D'Arcus has been talking about the flow of scholarly data and its metadata, so I thought I'd have a go at modelling the workflow I used most recently. Notice how the PDF sits up there in a dead end, bereft of any useful metadata.
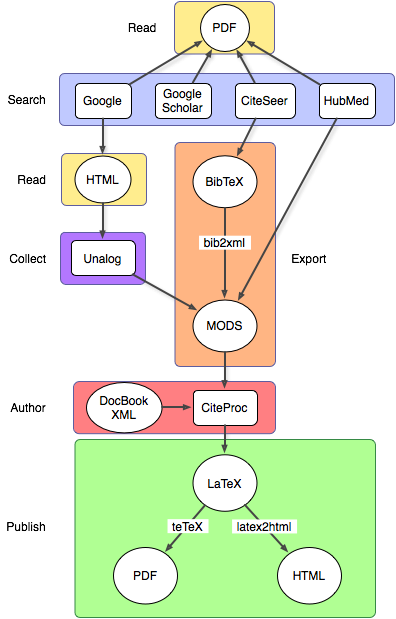
Bruce D'Arcus has been talking about the flow of scholarly data and its metadata, so I thought I'd have a go at modelling the workflow I used most recently. Notice how the PDF sits up there in a dead end, bereft of any useful metadata.