Timo Hannay gave a talk at EuroFoo called RSS Aggregation and Filtering - [Powerpoint slides]. Timo (with a bunch of other people) is working for Nature Publishing Group, who now produce RSS feeds for each of their journals, as well as for job listings, which contain extra job-specific metadata.
To deal with all this data floating around, including RSS feeds from other sites, they've created Urchin, an open-source RSS aggregator and filter. The demonstration version of Urchin pulls in data from a variety of sources and allows you to set up customised RSS feeds of this database using all kinds of search vocabulary.
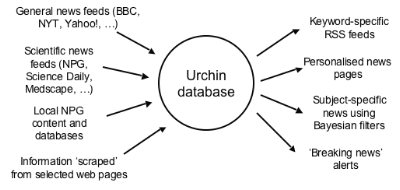
This allows you to create a feed from all the combined sources, containing only items that contained a particular term, such as this example feed. They're also working on a desktop version of Urchin that would allow you to filter incoming feeds within the aggregator, and use Bayesian filtering to show only those items that are the most interesting (word bursts and LSI are on the agenda too).
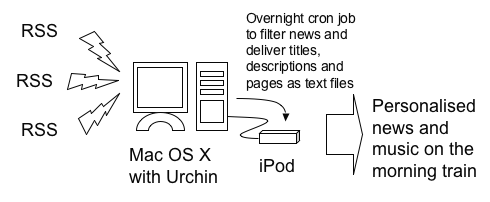
Timo also has ideas for a new project. I'm going to steal the diagram straight from the Powerpoint slide, again: